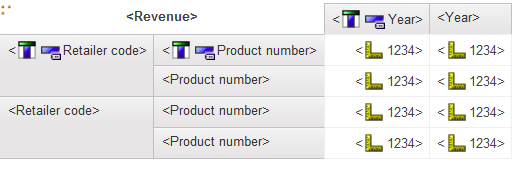
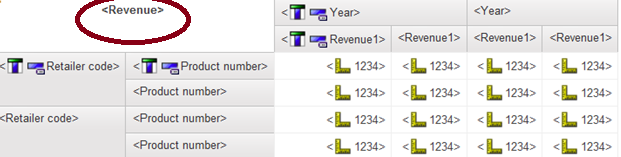
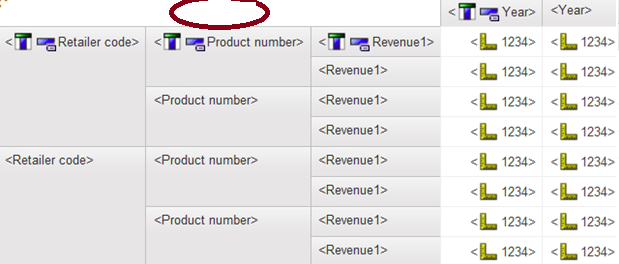
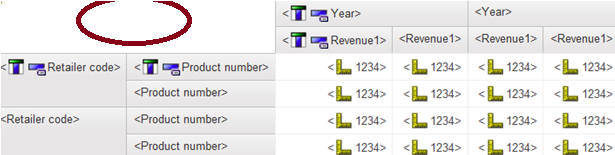
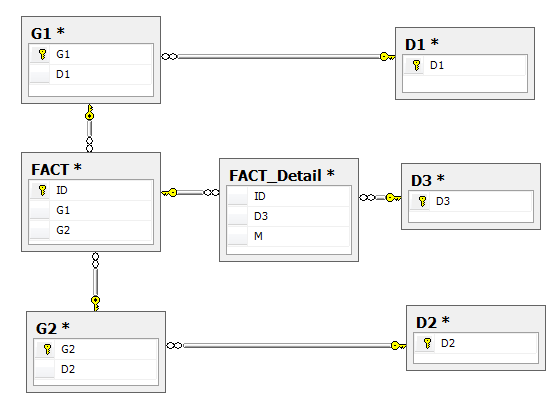
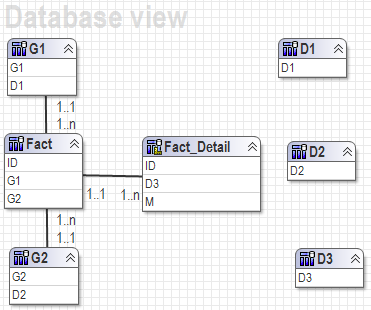
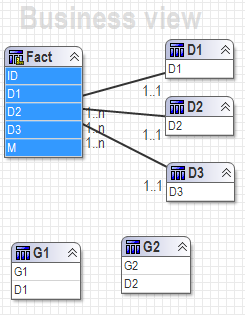
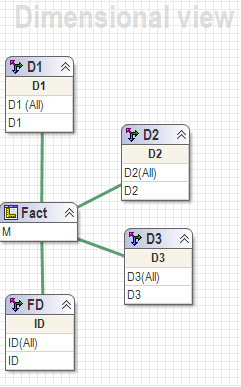
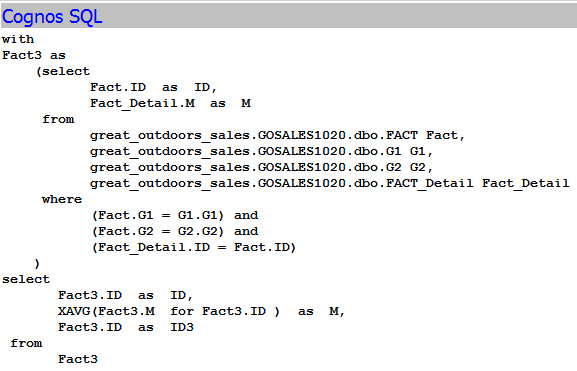
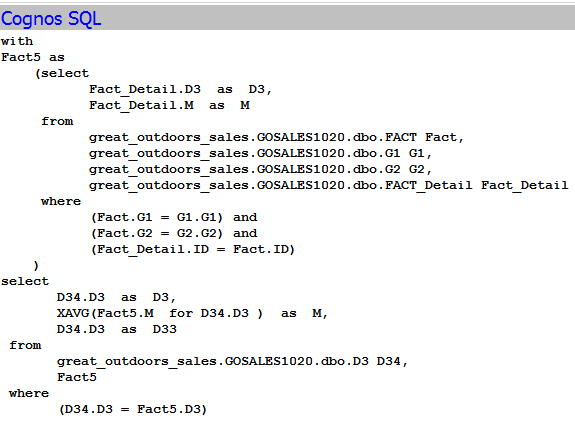
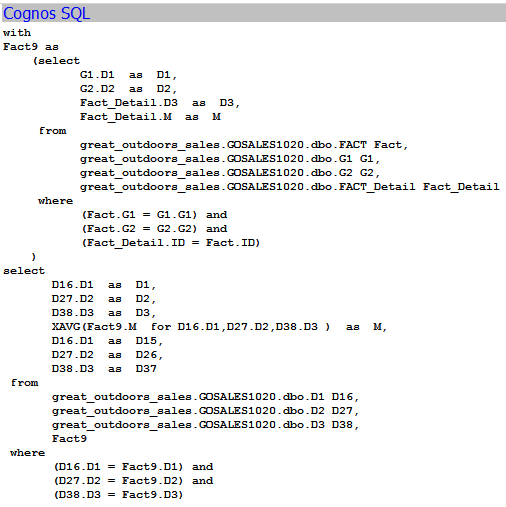
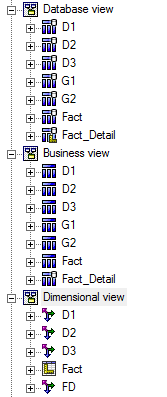
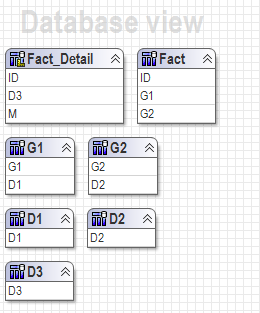
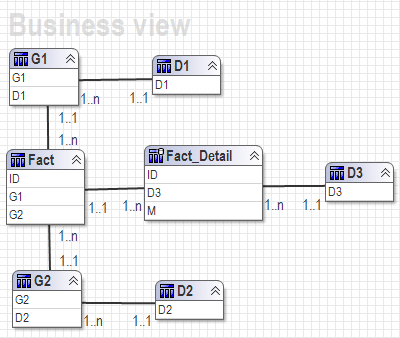
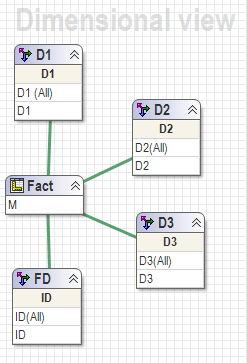
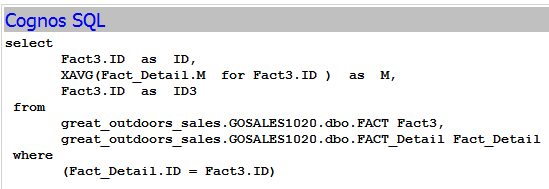
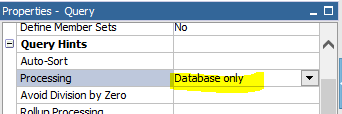
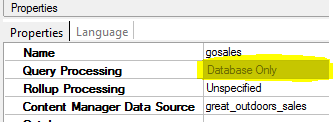
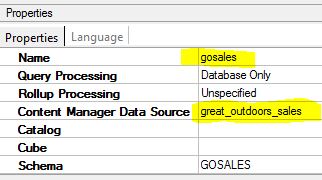
All these solutions are going to work based on two assumptions below
- Single physical database source. As long as all those involved tables can be joined together with single SQL query, we can considered it as single database source. It is obviously dependent on database kind, such as SQL server, oracle, DB2 and Netezza.
- No local process. Our focus is to generate single query for each data container. If there are more than one queries generated, then local processing is involved.
The criteria of most efficient SQL are defined as below
- Minimized SQL: only tables and columns that are used in report are listed in SQL query. for example, given that there are 10 dimensions and 1 fact in the model, and the fact table has 100 columns. Report select only one column from dimension and 1 column from fact, then the generated SQL should only have these two columns built into query. All other 9 dimensions should not be joined and used at all.
- No subquery, or WITH statement: The date filter is most frequently used. We want this date filter to be applied at the lowest level. In other word, database will filter data first and then join. Put filter at different level in SQL statement could result in 100 times difference of performance for big database.
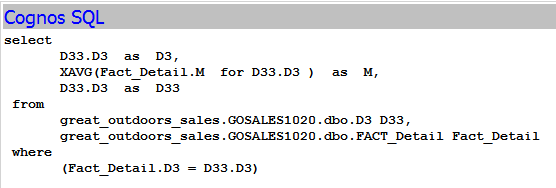
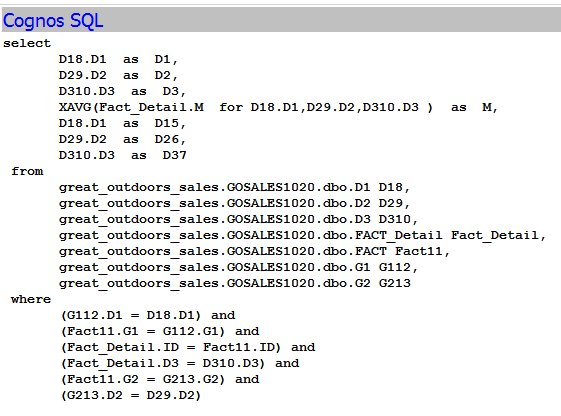
Sample
Below is a real example. Both FACT_ONE and FACT_TWO are about 600 million records, while all dimensions have about 1 million records. the generated query was changed from not efficient query to efficient query by remodelling Cognos Framework manager.
Before:Not Efficient Query - with problems
Query Result ->
UNION ->
SubQuery_ONE ->
JOIN
SubQuery_TWO (Filter at this level)
FACT_ONE (All columns)
SubQuery_THREE (Filter at this level)
SubQuery_FOUR
SubQuery_FIVE
SubQuery_SIX (Joined with 10 dimensions)
FACT_TWO (All columns)
SubQuery_ONE ->
JOIN ...
Problem 1 - has too many subqueries, which make filters NOT be applied at bottom level. Database needs to query 600 million records to join;Problem 2 - violate minimized query concept, even 10 dimensions are not used, but all dimensions join with fact table.
Problem 3- violate minimized query concept, even only a few columns are used, but all columns, more than 200 columns in this case, are selected.
Query Result ->
UNION ->
SubQuery_ONE ->
JOIN
FACT_ONE (needed columns, Filter at this level)
FACT_TWO (needed columns, Filter at this level)
SubQuery_ONE ->
JOIN ...
Some of solutions are listed below based on our consulting experience, which will be explained in detail in future blogs. Stay tuned.
- Problems with multiple data sources point to the same database: Even we have single physical database, but somehow local processing is involved. Behind the scene, Cognos considers it as two different database.
- At which layer should the relationship be created in Cognos Framework manager? database layer
- At which layer should filter(s) be added in Cognos Framework manager? business layer, while relationships are defined at database layer
- At which layer should a query column be derived in Cognos Framework manager? business layer, while relationships are defined at database layer
- What is the length of column limit in Cognos Framework Manager that generate subquery? 31