Please assume that the remote file is CSV or excel files in a shared folder; it is extremely slow to use a power query editor to code. This document provides two solutions with one of past projects to resolve this performance issue.
Case 1: There are many files to combine, and each file is huge, such as 0.5GB, and transform logic for each file is relatively simple.
Problem: If the network speed is poor between Power BI desktop and shared folder, each file could take even more than 1 hour to process. Moreover, if we want to process all files, it will take days to refresh the whole dataset on the desktop.
Solution: We need to copy all files into a local drive and process them to test the full results. To make our code generic, we must introduce a Folder Variable to use parameter-driven. Once tested, we can't directly publish it to Power BI services, as we still need to refresh the dataset against the remote files. We need to add the second parameter, the number of files to process to resolve this problem. We can specify a single file to process on the Power BI desktop; then, we can publish it to services and change the number of files to process as needed. The diagram below illustrates the process.

Case 2: There is only one file to process, and this file is not big, and transform logic is very complicated.
Problem: If the network speed is poor between Power BI desktop and shared folder, each file could take a long time to process. It is almost impossible to code.
Solution: We need to copy this file into a local drive and process it to test the full results. Again, to make our code generic, we must introduce a Folder Variable to use parameter-driven. Once tested, we can't directly publish it to Power BI services, as we still need to refresh the dataset against the remote file. The solution is to copy a tiny bit of this file into the remote folder and make a unique name convention. For the sake of explanation, we assume that we take the file with the highest BatchProcessID to process. For this tiny file, we can assign BatchProcessID =0 to name this file. This way, we need to add the second optional parameter. BatchProcessID specified, then we use BatchProcessID = 0 to filter file, otherwise use the file with the highest BatchProcessID. Then, we can publish it to services and remove this parameter. The diagram below illustrates the process. The diagram below shows the process.
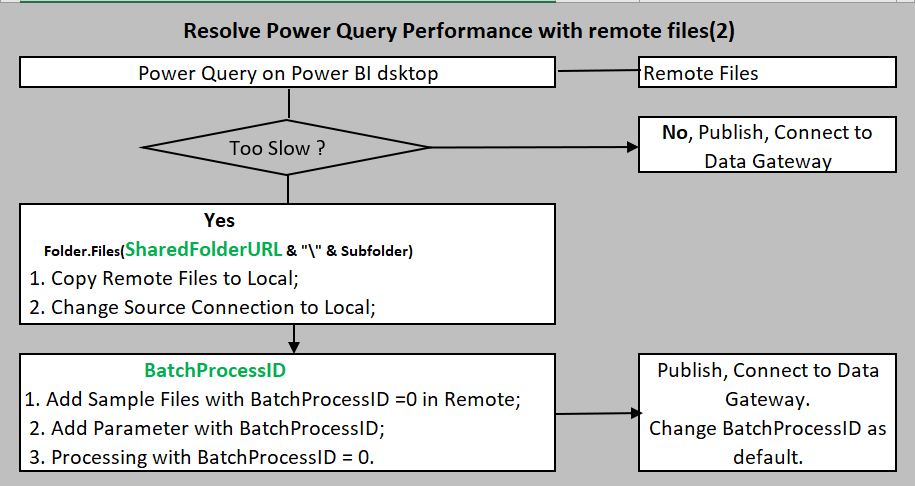

Note 1:
Sometimes when you try to change the Batch Processing ID, it takes a lot of time to change. So this case, you can remove all the big files from that folder and leave Batch Processing ID not specified. You don't need to change parameters anymore. You need to move all these big files to this folder.
Note 2:
Another general tip is to ONLY load columns as needed as early as possible in the query. For example, there are 100 columns, but only 10 columns are required. In this case, take only columns as needed at the beginning steps. However, this could result in a problem when columns in a file change sequence.
No comments:
Post a Comment