While current data flow works well with Cognos, it may not work well with Power BI. Why? Because Cognos is mainly SQL – driven, but Power BI is memory-driven. In addition, the language used for Cognos is mainly SQL, while Power BI uses DAX. Therefore, the database doesn’t play a significant role for Power BI from the process point of view.
To allow Power BI to take advantage of the data warehouse and then achieve the single version of the truth, we need to rethink data flow architecture. The bottom line is that we shouldn’t or can’t provide perfect data mart data for Power BI, as we deal with Cognos. IT is no longer controls and constrains every aspect of Power BI. In addition, we should also consider data prep functionality in Power BI. This functionality does make Power BI a winner against other analytical tools such as Tableau and QlikView. This functionality is Power Query (M-language); we can consider it a mini ETL tool. It is the responsivity of citizen developers from different business units.
The objective of the newly proposed data flow is to achieve a single data source but also establish a powerful presentation layer. At the same time, the architecture must be flexible to quickly adapt to changes when adding a new project or updating existing projects.
This document is intended to provide a pragmatic proposal based on current existing systems instead of considering the most advanced long-term architecture such as the lake house concept. Also, we are not proposing to move the whole system to the Azure cloud with Azure Synapse Analytics, along with the Azure data factory.
2. Challenges with Current Data Flow Architecture
Currently, we are in the process of developing many Power BI projects. However, all these projects are not in production yet with the Power BI data gateway to refresh automatically. To get data under control or achieve the single version of the truth, we are building good data mart data for Power BI. We are trying to push most data logic on the data warehouse side. Based on the limited knowledge, the current data flow architecture looks like the below at high level:

We understand that the current data flow is more complicated than displayed in the diagram above. We use database view from the data mart database to provide source data, and we also use Power BI data flow to provide good data for the Power BI model. We will refine the diagram once we learn it in detail. However, at the high level, Data imported for Power BI visualizations are from two different Channels:
Channel 1: Bypassing data warehouse, citizen developers directly extracted and transformed from data sources as spreadsheets or files; and
Channel 2: directly or indirectly load data from the data mart area from a data warehouse.
Problems with Channel 1
We can't keep the transform logic the same among different projects. So we will end up with varying results from other projects; therefore, we can't get the single version of the truth.
Also, we have done projects on an Ad-Hoc basis. As a result, we have not automatically refreshed dashboards with Power BI Gateway, which is not sustainable. In addition, we will waste our effort to create the same data, including dimensions and facts. So, for example, we need to figure out even the most fundamental data for each project, such as the date dimension with company calendar, employee, and WBS.
Problems with Channel 2
Channel 2 does overcome the problems of Channel 1. With Channel 2, we will get a single version of the truth, and we won't waste our effort, as data is from the data warehouse or a single data source. Is channel 2 is a good solution? This solution works from the theoretical point of view but doesn't work practically with current situations. The answer is that Channel 2 is not a good solution either. This answer is conditional upon the assumption that will use "import mode" for almost all cases.
First of all, this solution will make IT department overloaded. Currently, we have tried to put all this logic into a data mart. It could be a massive undertaking for the IT department, depending on the complexity of business logic.
Second, this solution will increase the time-to-delivery. Even when a business SME provides a clear logic, it will still take time to implement.
Third, the processing time will take much longer, assuming we will still use the Dell/Boomi tool. It could make the system overloaded or not stable at all.
Fourth, the system is very rigid; it is tough to change, such as adding new columns and tables, as we need to go to the staging and data mart process. Furthermore, this change may impact other tables or procedures, primarily if we have enforced all foreign key constraints in the database.
The bottom line is that we still need a data warehouse to have a single data source to achieve a single version of the truth. But we still need to reduce the workload for IT department and quickly adopt adding any new project, or changing existing projects, how?
3. Initial architecture proposal
The mission is to establish a single data source and a powerful Power BI presentation tier. In addition, we need to keep in mind that this architecture must be simple and flexible enough to adopt any new project quickly. As discussed in the last section, we can't use the data mart area data as the single data source. In other words, IT department can't build all data marts for all different projects. The diagram below is the new dataflow architecture, which tackles the challenge for business intelligence platforms.

This diagram defines four clear areas: source area, shared data area, Cognos area, and Power BI area. At the high level, this new data flow gives us two clear points:
1) Single data source, as all data are from shared data area in SQL server.
2) Powerful presentation layer, as we define the Power BI area as the combination of Power Query, shared Power BI datasets and Power BI visualizations
In addition, the new dataflow architecture puts business logic into both areas, the shared data area and Power Query / M area. This solution will reduce the IT department's workload, as the IT department will provide source data only, but not the whole data mart. At the same time, we also make the system much more flexible and agile.
We will explain the solutions in detail in the following four sections.
3.1 Solution 1: Segregate Cognos data flow from the data warehouse
As the current data flow is inherited from Cognos, we often consider Cognos engine and data warehouse together. However, we have specifically designed a data warehouse for the Cognos platform, including the staging and DataMart areas. The data mart area contains both primary data mart and aggregate data mart. Developing this way is because Cognos works the best with perfect data mart data. However, Power BI doesn't need a perfect data mart in the database because Power BI services work against memory engines or the vertipaq engine. VertiPaq is based on columns that are different from a basic SQL server. It can compress data in multiple ways and store that data into memory. The Diagram below shows the significant difference between Cognos and Power BI in processing.

We strongly suggest moving data mart areas into the Cognos area, as we don't need the data mart layer for Power BI.
The data mart is based on the Kimball method with surrogate keys and is already built and worked fine with Cognos. We do not suggest changing Cognos data flow architecture at all. We strongly recommend two points below:
1) Data Mart area is only going to serve Cognos data flow. When enhancing Cognos reports, we still need to improve the data mart to add/change data marts as needed.
2) Data Mart area is not needed for Power BI. We should NOT change the data mart when adding new Power BI projects or updating Power BI projects. We should not have a statement, such as we need to provide a data mart to satisfy new Power BI data requirements.
3.2 Solution 2: Establish a shared data area
We define the shared data area as the current data staging area extension. So, from the data warehouse concept point of view, we need to answer the first question: Why should we get rid of the data mart.
We all are familiar with current or traditional data warehouse architecture, which contains two significant steps at a high level: 1) extract data to staging tables from different data sources; and 2) transform and load data into data mart with surrogate keys.
The data mart layer initially provides two significant advantages: 1) we can get better performance using these surrogate keys to join the database. 2) We can handle slow changing dimension type 2, such as an employee changes sales department if we care department sales.
However, these two advantages are not very obvious anymore. 1) Surrogate keys are not necessary for boosting performance, given that database becomes more and more powerful, such as Azure synapse. More importantly, we move these data into a memory engine for Power BI. Surrogate keys become useless. 2) We can turn slow-changing dimension type 2 into type 1 if needed. For example, the employee dimension is a slow-changing dimension type 2 if we care for the department changes. The solution is to naturally add a department column into the sales fact table; in this case, we could consider the employee table as slow-changing dimension type 1 without a department column. Another solution is to make data with snapshot periods, and it will automatically track all department changes.
There are at least four advantages with this new concept:
1) Removal of data mart will reduce a significant step to load data; we can assume it will reduce process time by about 50%.
2) Compared with data mart, the new process becomes much easier to maintain and debug. We all know how difficult to troubleshoot data flow, as we must join all dimensions to get meaningful data.
3) The data mart definition is rigid and difficult to change. For example, if we want to add a new column or a new table, it could destabilize the whole data flow. At the staging area, we can consider each table as an independent. Power BI developers can transform data to define star schemes at the Power BI model level.
4) The data mart concept is like the old OLAP (multidimensional / MDX model), which is obsolete. Power BI becomes so powerful because it uses a more flexible tabular model instead of rigid OLAP.
5) As the whole BI industry moves from traditional ETL to modern ELT, leaving some Transformation logic into Power BI will make the system much more flexible.

Based on this discussion, we will have clear data areas defined below, where data mart is only located in the Cognos area.
Data is centralized as an authoritative source for reporting and analytics, regardless of Cognos or Power BI. We can see all data must be flow-through from the shared data area to enforce the single version of the truth. It is also the only channel we use at the enterprise level.
We can also ensure that all data areas have their data refresh engine. This new structure will shorten the refresh cycle because we remove the data mart and save processing time.
As we save some of the data in staging for delta data, we need to extend these data as a complete data set, mainly for fact tables. So, we will need to develop a clear development solution in detail.
3.3 Solution 3: Move specific transform logic to Power Query
The Query Editor in Power BI transforms or edits data files before loading data into the Power BI memory. The Query Editor plays the role of an intermediate data container where you can modify data by selecting rows and columns, splitting rows and columns, pivoting and unpivoting columns, etc. This functionality does make Power BI a winner against other analytical tools such as Tableau and QlikView. The question is whether we thoroughly move all transform logic to Power query. The answer in practice is probably no, as the best solution is to find a middle or happy ground. The diagram below lists three options for discussion.

It looks like we have applied both option 1 and option 2. The ideal solution is option 3. The basic rule lets Boomi/ETL handle generic logic as needed while allowing Power query to run project-specific logic. There are three cases to leave it to shared data area:
1) All conformed dimensions, such as Calendar, employee. We should keep many possible columns as needed. Then, when loading into Power BI, we can pick and choose only required columns and then further process.
2) The same goes for conformed facts.
3) In case when Power Query can't handle highly complex logic with massive data records, we still need to let Boomi/ETL take some project-specific logic if required.
Defining data structure between shared data area and Power BI data area is very different. While we want to keep all columns as much as possible, we want to load data into Power BI as little as possible. For example, we can have 100 columns of Calendar in a shared data area. On the other hand, we may need only 3 columns (year, month, and day) for some project areas.
We may need to answer why we don't suggest the Power BI data flow component, as we use it in the system. Below are a few reasons:
1) Power BI data flow could be beneficial if we don't have an SQL database or data warehouse. Power BI data flow loads data into ADLS2, behaves like a data warehouse. As we have a data warehouse, we don't need it.
2) Power BI data flow can encapsulate the shared transform logic, but it may not be necessary, as we will propose the shared dataset concept ( s. next section)
3) Power BI dataflow is challenging to use, compared with Power query with desktop. Their behaviour is different. Also, it is tricky to manage in terms of security on Power BI services.
4) Finally, we want to have our architecture simple and easy to implement.
Power BI dataflow might be very useful if uses ML/AI, as the data is better be saved in the data lake, also it is natively supported in the dataflow.
3.4 Solution 4: Enhance Power BI dataset as database
Power BI is simply very flexible; we could have a big problem managing it. To achieve data consistency in the Power BI area, we can consider the Power BI dataset as a database. The significant difference from the relational database, such as SQL server, is that this "database" is in-memory on the cloud and can be accessed by DAX. Power BI dataset is a winner of a BI semantic layer, which provides a powerful presentation layer. The diagram below lists its main usages:

Power BI dataset ensures business Logic is shared. We can make shared datasets available for report development in the same workspace or use another report space, where business users can develop visualizations as needed.
Besides, we can directly use Power BI as a data source with Power BI desktop; we can also directly connect the Power BI dataset with excel, then We can instantly create an excel spreadsheet based on this dataset;
Power BI datasets Support multiple applications based on XML/A. We can use SQL server management studio / Azure data studio to query this dataset; Power BI Premium also provides open-platform connectivity for Power BI datasets, with a wide range of data-visualization tools from different vendors. It means any third party, such as tableau, can consume (read) the Power BI datasets by reading and writing XMLA endpoints.
We can make the Power BI dataset reusable, like an object-oriented design. The Power BI dataset is like "Polymorphism, Encapsulation, Data Abstraction and Inheritance". This new functionality is called DirectQuery for Power BI datasets and Analysis Services, a fundamental change for Power BI model design, significantly impacting processing and data flow.
We have metadata and data in the shared data area to satisfy data requirements. We have provided the second area, or Power BI dataset, to have metadata and data. When a new project comes, we should check the Power BI dataset first in two steps:
1) Whether this Power BI dataset can serve the requirement or not? if not, then
2) Whether we can combine other Power BI datasets with satisfying requirements. This feature could be compelling for some cases, especially when you want to have enhancements
4. Problems of initial architecture proposal
While the initial proposal was acceptable for Power BI development, it doesn't work well for both Cognos and Power BI at the same time. There are a three problems:
1) The final result between Cognos and Power BI may not be the same; therefore, this architecture can't keep the single version of the truth. As you see in the initial architecture diagram below, the port of business logic is implemented from different pipelines. We use datamart on the Cognos side, while we use Power query on the Power BI side. Both sides could implement the same business logic differently. As a result, it is challenging to keep the logic in sync.

2) We have duplicated efforts to implement business logic for both Cognos and Power BI. The same business logic is implemented with Cognos's database in the DataMart area. This solution is not an intelligent proposal; the objective is to avoid duplicated efforts.
3) The initial proposal can’t fully leverage all Merlin investment. As we know, there has been a tremendous amount of effort on Cognos's side, and reports were approved and tested. The best idea should be to leverage whatever we have if we could. We need to let Power BI use all these approved and tested data.
The good news is that we all agree that the initial proposal works well with the Power BI side, which provides an agile system to allow a business to adopt Power BI quickly and efficiently.
This second-round proposal is to resolve all these three problems above. At the same time, we still keep all excellent architecture on the Power BI side. In addition, we are going to make a clear proposal according to the second-round proposal as first step to implement.
5. Introduction of term “Cognos data” and “Not Cognos data”, and assumption
We need to define two terms to resolve our problems: "Cognos data" and "Not Cognos data".
"Cognos data"
"Cognos data" is all data that currently exist in Merlin with conditions below
1) These data elements (Columns) are presented in the Cognos report to end-users.
2) Data elements (Columns) are not present in reports, but they are in the presentation layer in Cognos framework manager.
3) Although they are not in in the presentation layer the Cognos framework manager, but the table containing these data elements is used in Cognos data layers.
4) We may need more columns for these tables in the future to satisfy the business requirement; we still consider these tables as "Cognos data".
"Not Cognos data"
"Not Cognos data" refer to all data that doesn't belong to "Cognos data" defined as above. For example, from the database point of view, some tables are Cognos tables, while others are not Cognos tables, such as newly ServicesNow, S&T data.
Assumption
"Not Cognos data" will NOT be added into Cognos moving forwards. Even though we may enhance Cognos and fix errors for Cognos report, we will not add new data to Cognos reports. To be clear, we can add new columns to the existing table used in Cognos, but we will NOT add new tables to the Cognos framework manager.
Please note that "Cognos data" and "Not Cognos data" might not be good terms; we will refine them later. However, we use these two terms here for the sake of explanation.
6. Analysis 1: “Not Cognos data” only based data flow architecture
"Not Cognos data" will be ONLY used for Power BI based on the assumption. In this case, we only consider Power BI; our initial proposal works well as below by removing Cognos side. Again, please note "Not Cognos data” doesn’t flow on the Cognos side.

As illustrated , this architecture satisfies a single version of the truth. In addition, it is also an efficient platform to reduce the overload of IT department, as part of logic will be responsible from business units.
7. Analysis 2: “Cognos data” only based on architecture
These are the exact problems we have listed in the first section. To resolve all these problems, we welcome the current approach from the IT department to push logic from Cognos framework manager, if any, into a data mart. Please refer to the diagram below.

We won't put any logic in the Power query area on the Power side. Instead, we implement all logic from the datamart area. Doing this way, we will resolve all 3 problems listed at the beginning.
1) The final result between Cognos and Power BI will be the same. We don't implement any logic on the Power query. Instead, we have centralized on the data mart area as approved. As a result, there won't be any problem keeping logic in sync between Cognos and Power BI.
2) We don't have duplicated efforts to implement business logic, as we use whatever data that were approved and tested.
3) We have 100% leveraged all our existing codes. So all the efforts won't be wasted at all. All these hard-working and all decisions are 100% inherited.
8. Analysis 3: both “Cognos data” and “Not Cognos data” mixed data flow architecture
Now, we have got third case, which is the mixed model. As we know, the same Power BI dashboards may need data from "Cognos data" and "Not Cognos data". The idea is to stitch both data together by introducing a "Switch". This switch control which way to go on the database side. Please refer to the diagram below.

As illustrated, Cognos only uses "Cognos data", and Cognos must not use "Not Cognos data" at all, which was our primary assumption in the second section. We will have both "Cognos data" and "Not Cognos data" in the database. Power BI will mush up both data together with a clear star scheme if needed.
1) As this diagram inherited the idea from "Cognos data" only data flow concept, the final result between Cognos and Power BI will be the same if the power BI side has some data used on the Cognos side. "Cognos data" and "Not Cognos data" are mutually exclusive.
2) We don't have duplicated efforts to implement business logic. For "Not Cognos data" data flow, though the logic will be distributed between database and Power query.
3) We have fully leveraged all our existing codes. So all the efforts won't be wasted. All these hard-working and all decisions are 100% inherited. We only need to be mindful to decide whether it is "Cognos data", or "Not Cognos data".
9. Solution: New dataflow architecture
Based on all analysis above, we can figure out the new solution based on the mixed data flow architecture. We introduce the new data flow architecture diagram below to make the data flow flexible and robust.
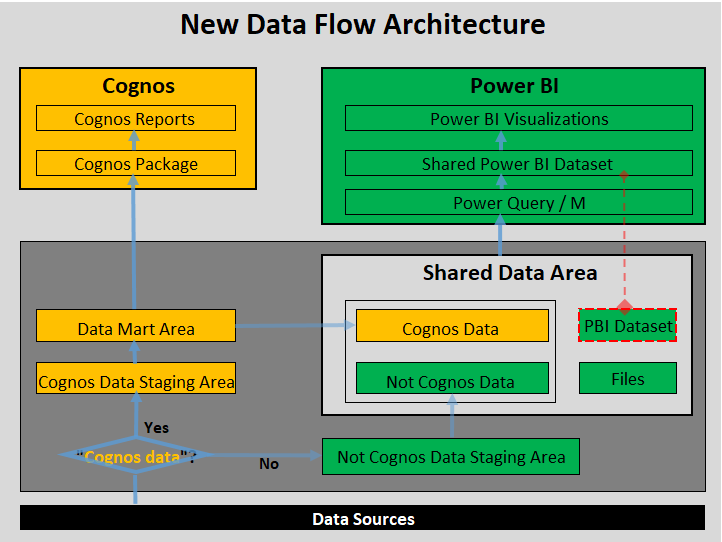
At the high level, we have resolved the report data discrepancy issue between Cognos and Power BI, avoided duplicated efforts, and fully leveraged all current investments. This diagram illustrates all four points listed below:
1) We have separated data flows as a separated pipeline: "Cognos data" data flow and “Not Cognos data" data flow. The "Cognos data" data flow contains three steps: step from source to staging, step from Staging to Datamart, and step from Datamart to “Cognos data." The "Not Cognos Data" data flow eliminates Datamart; it has only two steps: step from source to staging and step from staging to "Not Cognos Data". This separation will be very beneficial to data management, such as we can have different schedules as needed.
2) The way to design "Not Cognos data” data flow is different from "Cognos Data”: data flow by three different approaches, listed below:
a) "Not Cognos data” data flow doesn't have the data mart step, as it is unnecessary. Please refer to the initial proposal for detailed explanations about why we don’t want to have a datamart with surrogate keys. .
b) "Not Cognos data” data flow doesn't contain all business logic. Instead, it handles only the generic logic as needed while allowing Power query to run project-specific logic. The typical data are all conformed dimensions, facts, and data with complicated logic with massive data records when Power query can't handle it.
3) We should establish a shared data area, which should have all correct data from all these different source systems extracted and loaded. In addition, all these tables should be harmonized and managed with a clear refresh schedule. There are two other data kinds besides "Cognos data" and "Not Cognos Data": Power BI datasets and Files.
a) We should keep many possible columns as needed; when loading into Power BI, we should load the number of columns as little as possible. For example, we can have 100 columns of Calendar. On the other hand, we may need only 3 columns (year, month, and day) for some project areas.
a) The Power BI dataset can behave as an object-oriented program, “Polymorphism, Encapsulation, and Inheritance". Compared with Cognos, it is like a Cognos package inheritance from another Cognos Package, which doesn't exist in Cognos. This new functionality is called DirectQuery for Power BI datasets and Analysis Services, a fundamental change for BI model design, significantly impacting processing and data flow. Simply put, we can consider any Power BI datasets as a data source, which could dramatically improve the Power BI development processes.
b) Files, whether a spreadsheet or CSV, can also be added as a Power Data source. Sometimes, we don't need to load primary reference data into the database. Instead, we can leave them as files efficiently to move a project quickly. Power query is an excellent engine to mush up these data at that level.
4) We don't suggest the Power BI data flow component, which can be discussed in more detail.
a) Power BI data flow could be beneficial if we don't have an SQL database or data warehouse Power BI data flow loads data into ADLS2, behaves like a data warehouse. As we have a data warehouse, we don't need it.
b) Power BI data flow can encapsulate the shared transform logic, but it may not be necessary when using the shared dataset concept.
c) Power BI dataflow is challenging to use, compared with Power query with desktop. Their behaviour is different. Also, it is tricky to manage in terms of security on Power BI services.
No comments:
Post a Comment