Power BI performance is critical in Power BI projects, including Power Query, data model, and visualization performance. Power Query performance refers to two kinds of performance: one is development performance, and another one is dataset refresh performance. Unfortunately, in real projects, Power query is not easy to use if data is big. This document is to share some of my experience as a Power BI consultant with different clients. We can't find such solutions on Microsoft's official site.
We define development performance as the speed of Power Query editor speed, mainly how quickly a power query editor gets a preview for each step. For example, if the Power query preview of each step takes a few minutes, it will dramatically reduce the productivity of development and frustrate Power BI developers. Furthermore, if the data is huge and logic is complicated, such as group by and pivot, the Power BI desktop can't handle it.
Dataset refresh performance is determined by the duration of a dataset refreshed on Power BI services. We know this performance can be impacted by the data model too. However, we are discussing the impact from the Power Query point of view.
While we know some best practices, such as query folding, Filtering early, Making expensive operations last, and creating reusable functions. we are discussing three special solutions to speed up Power BI development performance:
Improve development performance with Power BI desktop
Solution 1: Reduce file size.
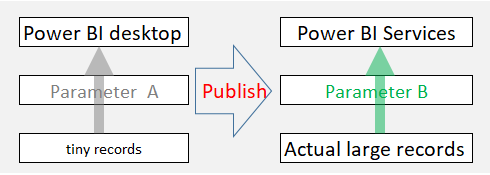
Assuming that many files are in a shared drive and they are big, we can connect and process them. However, the Power query editor takes forever to load the data in the preview. The easy solution is to copy remote files to a local PC, but it may take a lot of time to copy the data, or the local PC may not have enough memory to handle the process. In addition, we still need to process the whole data on Power BI services. The best solution is to derive a tiny subset of data as a file in a remote drive or make such a tiny file on a local PC. please make sure that such a tiny file should reflect the file structure and cover the combination as needed. Then, we can do the development with this tiny file and process it with actual files on Power BI services when published. Please refer to the diagram below for the idea. Also, please refer to the link for detail. What to do when the Power query editor and refresh is so slow with remote files?

Solution 2: Use tiny sample records from a database.
Assuming that a table is big and can't proceed with incremental loading, we can connect and process this table but request a PC with powerful CPUs and more memory, or we use a virtual server to handle it. The development is challenging when we want more logic, such as group by and merge queries. The best solution is to use a small sample query with a native query. Again, please ensure that such a tiny file reflects the file structure and covers the combination as needed. Then, we can develop this small query and process it with an actual table on Power BI services when published. Please refer to the diagram below for the idea. Also, please refer to the link for detail. What to do when the Power Query editor and refresh are very slow with large data volume?
Solution 3: Use Power BI dataflow
Assuming that there are a lot of queries (my experience is about 200+), the Power query editor becomes very slow to react. Typically, many similar queries are based on some shared logic, such as some conformed dimensions and facts. Power BI dataflow can be used here to speed up overall development performance. Power BI dataflow has made data available, saving time processing different queries.

Improve dataset refresh performance with Power BI services
Concerning dataset refresh, We are discussing two unique solutions to speed up Power BI dataset performance. BTW, we are not talking about traditional solutions such as reducing dataset size by removing not needed columns.
Solution 4: Apply Power BI incremental loading with large files and tables
We can check the document from Microsoft to get the definition and benefit for incremental loading. Based on my experience, incremental refresh can do much more than described on the Microsoft site, assuming that we are not doing real-time refresh.
Based on microsoft site, incremental refresh is designed for data sources that support query folding, which is Power Query's ability to generate a single query expression to retrieve and transform source data. Most data sources that support SQL queries support query folding. However, data sources like flat files, blobs, and some web feed often do not. My finding is that this statement is not true, in other words, data sources like flat files and native queries are supported by incremental refresh. The incremental refresh will work if you can put RangeStart and RangeEnd into Power Query logic. Furthermore, we don't need to use RangeStart and RangeEnd directly, we can use the functions to turn RangeStart and RangeEnd to whatever is needed, such as YYYYMMDD format. Obviously, we need to make sure that the query makes sense, especially for the merge query. Please refer to the diagram below for the idea. Also, please refer to the link for detail. Unleash the power of Power BI incremental refresh

Even with dataset full refresh, incremental refresh could perform better for the database, as we partition data behind the scene, piece by piece, based on the incremental refresh policy.
Solution 5: Avoid reference query
A reference query is a solution to share the same logic; however, if that query handles large data with complicated logic. Then query with reference has to go through that large data with complicated logic again. Let's use a sample to explain this idea, given that we have two queries, one fact and one dimension, and both from a single large file with 100 columns. We can do it with two different approaches; one is with reference, and another one develops two queries independently. The diagram below illustrates the execution effort. The approach without reference query will remove the duplicated execution.

No comments:
Post a Comment